Patch2Self: Self-Supervised Denoising via Statistical Independence
Hello everyone! In this post, I will explain our work Patch2Self [1] which was accepted as a Spotlight Presentation at Neural Information Processing Systems Conference, 2020: https://papers.nips.cc/paper/2020/hash/bc047286b224b7bfa73d4cb02de1238d-Abstract.html
I will be describing the following three key points of innovation for Patch2Self aimed at both Machine Learning and Medical Image/Signal Processing audience:
- It uses self-supervised learning to denoise the data leveraging the fact that noise in the data is statistically independent.
- It provides a fundamentally new perspective on Diffusion MRI data, that reveals the nature of the redundancy in the data. We show how one can learn to represent each 3D volume of the 4D data as a linear combination of the other volumes.
- Patch2Self simplifies the problem, is parameter-free, fast and works on all types of Diffusion MRI data. Open-source implementation has been made available in DIPY with “1 simple command”. It runs in seconds and has a very easy-to-use, well-tested Pythonic API!
Section 1: Self Supervised Learning and Statistical Independence.
Need? Until recently, image denoising as a sub-domain of image processing was dominated by methods trying to leverage certain properties of the signal structure. By this I mean, models were used to approximate the underlying signal using assumption such as smoothness [2, 3], sparsity [6, 7], self-similarity/ repetition [2, 4, 5], etc. Diffusion MRI being “medical” image processing is no different and has had popular methods revolving around the same idea [8, 9, 10, 11]. (Note: these references are not a complete list! There’s a lot more…)
Relevant work: In ICML’18, Noise2Noise [12] first made use of the idea of statistical independence for image denoising. They showed that if you had 2 different noisy samples of an object, you can use one noisy measurement to predict the other noisy measurement. By doing so, what one ends up learning is a denoiser. Why? The model used for learning, cannot learn noise!

This is great! This shows how one can basically flip the signal representation assumption of the denoiser on the noise rather than the signal, which is the primary reason for signal/ data degradation.
- Statistical independence allows you to go “model-free”: One does not need to model the noise or the signal.
- As long as noise is randomly fluctuating and the approximation system you use to train is good enough, you are guaranteed to get denoising performance.
Furthering this line of research, in Noise2Self (ICML’19) Joshua Batson et.al. [13] showed that one doesn't even require an “image-pair” to do the denoising. Laying out a simple and elegant theory of J-invariance, Noise2Self showed how one can use self-supervision by blocking out a set of dimensions from the image and train only on those dimensions to learn a denoiser for the entire image!

In Diffusion MRI, we apply the above ideas:
- We have independent image examples of the same subject (in this post the “Human Brain”), multiple 3D volumes in the same scan: resulting in a 4D image (see image below in section 2).
- If we treat the 4D scan as 1 image, each of the 3D volumes in the scan are “J-invariant” (explained in section 2). This allows us to use a self-supervised loss along the 4th dimension as described below.
Section 2: Patch2Self Learning Framework
Let's take a look at what Diffusion MRI data looks like, and certain signal properties that we have leveraged in the design of Patch2Self:

As you can see, although we acquire different 3D images of the same object they contain different information owing to the gradient direction of the particular volume. The above dataset contains 150 diffusion-weighted volumes corresponding to different gradient directions and can be visualized as follows in the q-space:
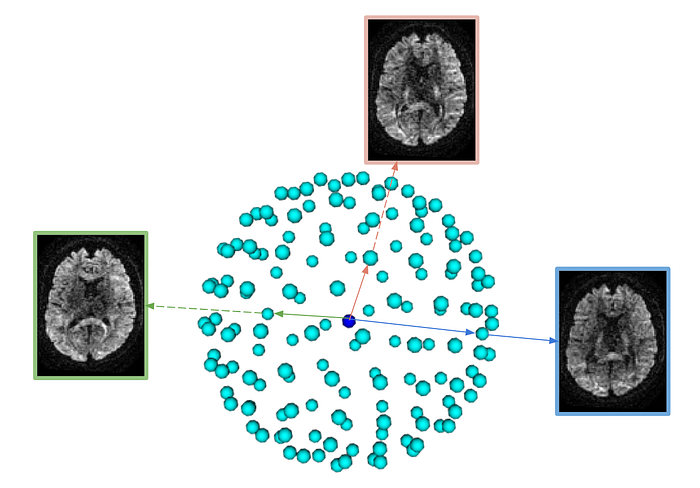
Given that we have ‘‘n’’ 3D volumes, and is oversampled in q-space , we propose learning to represent each of the 3D volume as a combination of the “n-1” volumes. We show that a simple “linear regression” does super well, given the abundance of information. This is also not surprising given the previous successes of [9, 10]
In Patch2Self, NeurIPS’20 [1], we propose a simple, fast and self-supervised methods that uses the following strategy:
Idea: Noise exhibits statistical independence across different dimensions of the measurement, while the true signal exhibits some correlation.
Therefore, we train one separate regressor to denoise each target volume!
Note: This algorithm works with 3D patches.
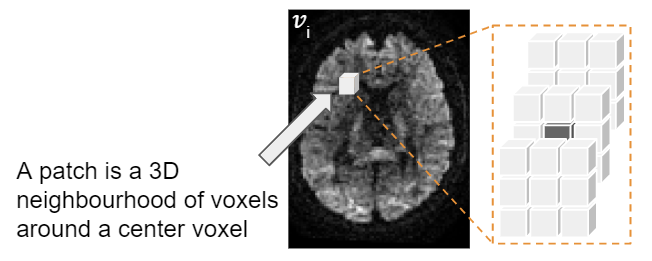
- Starting with the 4D data, we extract 3D Patches from all the “n” volumes and hold out a target volume (all patches corresponding to it) to denoise as follows:
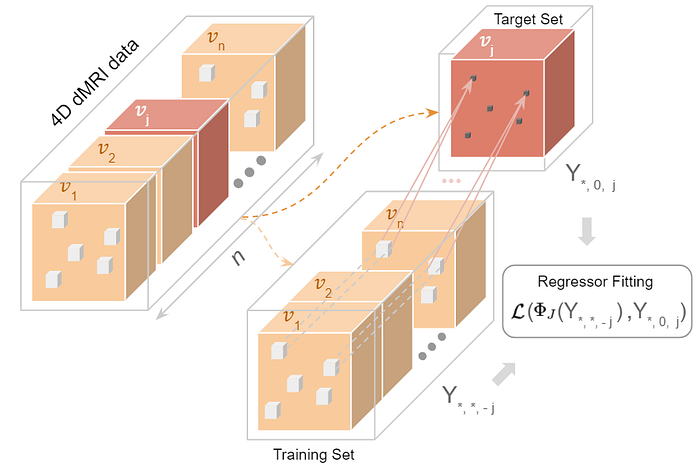
Regression Training:
Each patch from the rest of the ‘(n-1)’ volumes predicts the center-voxel of the corresponding patch in the target volume.
The regression function that we learn in the process has learnt how to predict the held-out volume, given the rest of the volumes.
J-Invariant Self-supervised Loss for Regression Training:
The loss used in the regression function above works only if it satisfies a particular property: J-invariance. This is the crux of what essentially gives the denoising performance! What J-invariance implies is:
- If the noise in J “held-out” dimensions is independent of the noise in other dimensions, then, we can build an optimal denoiser by using the “held-in” dimensions to predict the “held-out” J dimensions. This loss can mathematically be represented as follows:

Trained Regressors Output Denoised Volumes:
To get the denoised version of the held-out volume, we feed in the same “n-1” volumes into the regression function Phi to get the denoised version. This is what happens under the hood:
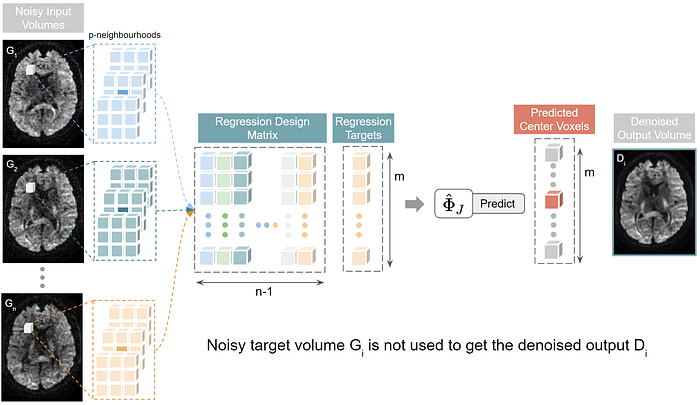
Voila! By repeating this process for all 3D volumes, in no time, we have denoised the whole data!
Since I already gave the q-space analogy, this is what J-invariant training looks in q-space looks like:
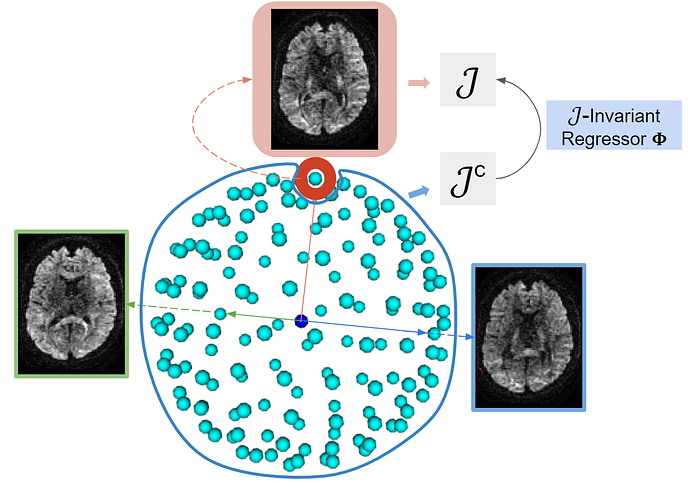
Now let's take a look at some results:
Patch2Self Suppresses Noise and Preserves Anatomical Detail
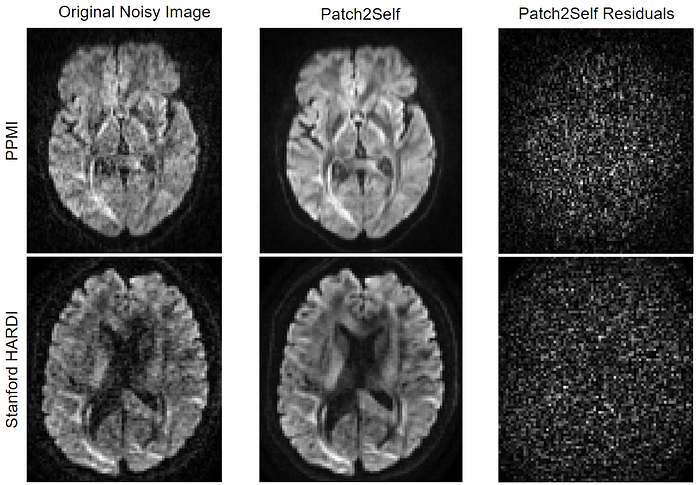
For the above datasets, we show the axial slice of a randomly chosen 3D volume and the corresponding residuals (squared differences between the noisy data and the denoised output).
Notice that Patch2Self, do not show any anatomical features in the error-residual maps, showing no structural artifacts. Patch2Self produced more visually coherent outputs, which is important as visual inspection is part of clinical diagnosis.
The number of incoherent streamlines is reduced after Patch2Self
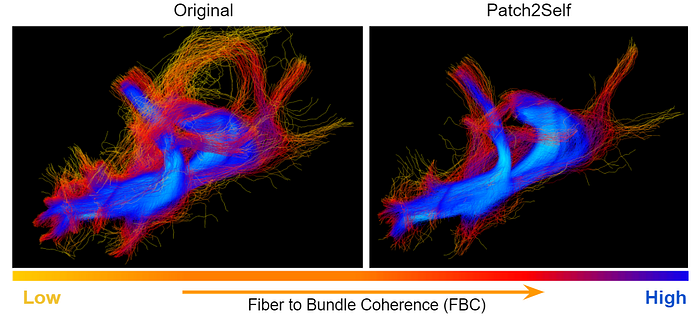
We make use of the Fiber to Bundle Coherency (FBC) density map [14] projected on the streamlines of the optic radiation bundle generated by the probabilistic tracking algorithm in DIPY [15].
The color of the streamlines depicts the coherency − yellow corresponding to incoherent and blue corresponding to coherent. Notice that Patch2Self denoising reduces spurious tracts, giving a cleaner and coherent representation of the fiber bundle.
Patch2Self has been made available in DIPY using with a well-tested and easy to use Python. We have created a simple command-line interface and can be used in merely 2 steps:
First, install DIPY:
pip install -i https://pypi.anaconda.org/scipy-wheels-nightly/simple dipy
The above wheel is a dev-version of DIPY, since the official DIPY release if after NeurIPS’20, sometime around the end of December. If you are reading this post after December’20, please use:
pip install dipy — This should install DIPY with Patch2Self in it!
Patch2Self also requires scikit-learn
Command Line Interface
Here is the command-line argument that you can run on your terminal:
dipy_denoise_patch2self your_data.nii.gz your_data.bval --out_denoised denoised_your_data.nii.gz
Takes data in Nifti file format and the associated bval file as shown above.
The denoised output will be saved as denoised_your_data.nii.gz If you want to see the other command-line interface options type: dipy_denoise_patch2self -h
For Python API:
You can run Patch2Self in DIPY as follows:
# To handle file handling
import numpy as np
from dipy.io.image import load_nifti, save_nifti# Load the Patch2Self module from DIPY
from dipy.denoise.patch2self import patch2self# Load your data!
data, affine = load_nifti('your_data.nii.gz')
bvals = np.loadtxt('your_data.bval')# Run Patch2Self denoising
denoised_data = patch2self(data, bvals, verbose=True)# save the data
save_nifti('denoised_your_data.nii.gz', denoised_data, affine)
Wrap-up: Why use Patch2Self?
- Self-supervised, parameter-free and works with a single subject.
- Works with any number of Diffusion Volumes.
- Can be applied at any point of the pre-processing. As long as the noise in the data remains random, Patch2Self will give denoising performance.
- Uses statistical independence to perform the denoising, preserves the anatomical structure in the data.
- Works with any type of diffusion data and acquisition on any body part, animal, etc.
References:
[1] Fadnavis, et. al, “Patch2Self: Denoising Diffusion MRI with Self-Supervised Learning”, Advances in Neural Information Processing Systems 33 (2020).
[2] Buades, Antoni, Bartomeu Coll, and J-M. Morel. “A non-local algorithm for image denoising.” 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). Vol. 2. IEEE, 2005.
[3] Rudin, Leonid I., Stanley Osher, and Emad Fatemi. “Nonlinear total variation based noise removal algorithms.” Physica D: nonlinear phenomena 60.1–4 (1992): 259–268.
[4] Ulyanov, Dmitry, Andrea Vedaldi, and Victor Lempitsky. “Deep image prior.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[5] Dabov, Kostadin, et al. “Image denoising by sparse 3-D transform-domain collaborative filtering.” IEEE Transactions on image processing 16.8 (2007): 2080–2095.
[6] Papyan, Vardan, Yaniv Romano, and Michael Elad. “Convolutional neural networks analyzed via convolutional sparse coding.” The Journal of Machine Learning Research 18.1 (2017): 2887–2938.
[7] Elad, Michael, and Michal Aharon. “Image denoising via sparse and redundant representations over learned dictionaries.” IEEE Transactions on Image processing 15.12 (2006): 3736–3745.
[8] Coupé, Pierrick, et al. “An optimized blockwise nonlocal means denoising filter for 3-D magnetic resonance images.” IEEE transactions on medical imaging 27.4 (2008): 425–441.
[9] Manjón, José V., et al. “Diffusion weighted image denoising using overcomplete local PCA.” PloS one 8.9 (2013): e73021.
[10] Veraart, Jelle, Dmitry S. Novikov, Daan Christiaens, Benjamin Ades-Aron, Jan Sijbers, and Els Fieremans. “Denoising of diffusion MRI using random matrix theory.” Neuroimage 142 (2016): 394–406.
[11] Knoll, Florian, et al. “Second order total generalized variation (TGV) for MRI.” Magnetic resonance in medicine 65.2 (2011): 480–491.
[12] Lehtinen, Jaakko, et al. “Noise2Noise: Learning Image Restoration without Clean Data.” International Conference on Machine Learning. 2018.
[13] Batson, Joshua, and Loic Royer. “Noise2Self: Blind Denoising by Self-Supervision.” International Conference on Machine Learning. 2019.
[14] Portegies, Jorg M., et al. “Improving fiber alignment in HARDI by combining contextual PDE flow with constrained spherical deconvolution.” PloS one 10.10 (2015): e0138122.
[15] Garyfallidis, Eleftherios, et al. “Dipy, a library for the analysis of diffusion MRI data.” Frontiers in neuroinformatics 8 (2014): 8.